generated by jekyll-scholar.
2025
-
 The Canon in Circulation: Tracking the Reception of Norton Anthology Authors in Library Checkout DataNeel Gupta, Daniella Maor, Karalee Harris, Emily Backstrom, Hongyuan Dong, and Melanie WalshIn Computational Humanities Research, Dec 2025
The Canon in Circulation: Tracking the Reception of Norton Anthology Authors in Library Checkout DataNeel Gupta, Daniella Maor, Karalee Harris, Emily Backstrom, Hongyuan Dong, and Melanie WalshIn Computational Humanities Research, Dec 2025Which canonical American authors are the public reading, and why? We explore this question by analyzing nearly two decades of book circulation data from the Seattle Public Library (SPL), one of the only public libraries in the United States to make anonymized checkout data publicly available. Focusing on the 93 authors included in the post-1945 volume of The Norton Anthology of American Literature (NAAL), we examine 1.6k unique works and almost one million checkouts to better understand contemporary literary reception beyond the classroom. We present a novel dataset that can support future reception research and serve as a benchmark for future Work-level clustering approaches. Our findings suggest that the few genre fiction authors in the NAAL—particularly writers of science fiction—dominate the checkouts, and that circulation spikes are often triggered by high-profile media adaptations, the death of an author, and potentially even scandal. We share an open-source, interactive tool that allows users to explore checkout trends for any post-1945 NAAL author or work over the last 20 years.
@inproceedings{guptaCanonCirculationTracking2025, title = {The {{Canon}} in {{Circulation}}: {{Tracking}} the {{Reception}} of {{Norton Anthology Authors}} in {{Library Checkout Data}}}, shorttitle = {The {{Canon}} in {{Circulation}}}, booktitle = {Computational {{Humanities Research}}}, author = {Gupta, Neel and Maor, Daniella and Harris, Karalee and Backstrom, Emily and Dong, Hongyuan and Walsh, Melanie}, editor = {Arnold, Taylor and Fantoli, Margherita and Ros, {and} Ruben}, year = {2025}, volume = {3}, pages = {1510--1522}, month = dec, doi = {10.63744/P6qPH135jhY2}, urldate = {2025-12-10}, ach = {https://anthology.ach.org/volumes/vol0003/the-canon-in-circulation-tracking-reception-of-in/}, } -
 BookReconciler📘💎: An Open-Source Tool for Metadata Enrichment and Work-Level ClusteringMatt Miller, Dan Sinykin, and Melanie WalshIn Joint Conference on Digital Libraries, Dec 2025
BookReconciler📘💎: An Open-Source Tool for Metadata Enrichment and Work-Level ClusteringMatt Miller, Dan Sinykin, and Melanie WalshIn Joint Conference on Digital Libraries, Dec 2025We present BookReconciler, an open-source tool for enhancing and clustering book data. BookReconciler allows users to take spreadsheets with minimal metadata, such as book title and author, and automatically 1) add authoritative, persistent identifiers like ISBNs 2) and cluster related Expressions and Manifestations of the same Work, e.g., different translations or editions. This enhancement makes it easier to combine related collections and analyze books at scale. The tool is currently designed as an extension for OpenRefine—a popular software application—and connects to major bibliographic services including the Library of Congress, VIAF, OCLC, HathiTrust, Google Books, and Wikidata. Our approach prioritizes human judgment. Through an interactive interface, users can manually evaluate matches and define the contours of a Work (e.g., to include translations or not). We evaluate reconciliation performance on datasets of U.S. prize-winning books and contemporary world fiction. BookReconciler achieves near-perfect accuracy for U.S. works but lower performance for global texts, reflecting structural weaknesses in bibliographic infrastructures for non-English and global literature. Overall, BookReconciler supports the reuse of bibliographic data across domains and applications, contributing to ongoing work in digital libraries and digital humanities.
@inproceedings{miller-2025-bookreconciler, title = {BookReconciler📘💎: An Open-Source Tool for Metadata Enrichment and Work-Level Clustering}, author = {Miller, Matt and Sinykin, Dan and Walsh, Melanie}, tutorial = {https://youtu.be/V9ZJoFowRJM}, booktitle = {Joint Conference on Digital Libraries}, month = dec, year = {2025}, publisher = {ACM/IEEE}, } -
 so much depends / upon / a whitespace: Why Whitespace Matters for Poets and LLMsSriharsh Bhyravajjula, Melanie Walsh, Anna Preus, and Maria AntoniakIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Nov 2025
so much depends / upon / a whitespace: Why Whitespace Matters for Poets and LLMsSriharsh Bhyravajjula, Melanie Walsh, Anna Preus, and Maria AntoniakIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Nov 2025Whitespace is a critical component of poetic form, reflecting both adherence to standardized forms and rebellion against those forms. Each poem’s whitespace distribution reflects the artistic choices of the poet and is an integral semantic and spatial feature of the poem. Yet, despite the popularity of poetry as both a long-standing art form and as a generation task for large language models (LLMs), whitespace has not received sufficient attention from the NLP community. Using a corpus of 19k English-language published poems from Poetry Foundation, we investigate how 4k poets have used whitespace in their works. We release a subset of 2.8k public-domain poems with preserved formatting to facilitate further research in this area. We compare whitespace usage in the published poems to (1) 51k LLM-generated poems, and (2) 12k unpublished poems posted in an online community. We also explore whitespace usage across time periods, poetic forms, and data sources. Additionally, we find that different text processing methods can result in significantly different representations of whitespace in poetry data, motivating us to use these poems and whitespace patterns to discuss implications for the processing strategies used to assemble pretraining datasets for LLMs.
@inproceedings{bhyravajjula-etal-2025-much, title = {so much depends / upon / a whitespace: Why Whitespace Matters for Poets and {LLM}s}, author = {Bhyravajjula, Sriharsh and Walsh, Melanie and Preus, Anna and Antoniak, Maria}, editor = {Christodoulopoulos, Christos and Chakraborty, Tanmoy and Rose, Carolyn and Peng, Violet}, booktitle = {Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.emnlp-main.1783/}, pages = {35144--35161}, isbn = {979-8-89176-332-6}, acl = {https://aclanthology.org/2025.emnlp-main.1783/}, } -
 Introducing the Anthology for Computers and the HumanitiesTaylor Arnold, Maria Antoniak, Miguel Escobar Varela, Marie Puren, Mila Oiva, Amanda Regan, and 2 more authorsAnthology of Computers and the Humanities, Sep 2025
Introducing the Anthology for Computers and the HumanitiesTaylor Arnold, Maria Antoniak, Miguel Escobar Varela, Marie Puren, Mila Oiva, Amanda Regan, and 2 more authorsAnthology of Computers and the Humanities, Sep 2025We present the \emph\textbraceleft Anthology of Computers and the Humanities\textbraceright, a new publication designed to host open-access, peer-reviewed proceedings from digital humanities (broadly defined) conferences and workshops. The \emph\textbraceleft Anthology\textbraceright provides a home for conference proceedings, offering essential structures such as DOIs and searchability, while being explicitly attuned to the needs of research situated in humanities disciplines.
@article{arnoldIntroducingAnthologyComputers2025, title = {Introducing the {{Anthology}} for {{Computers}} and the {{Humanities}}}, author = {Arnold, Taylor and Antoniak, Maria and Varela, Miguel Escobar and Puren, Marie and Oiva, Mila and Regan, Amanda and Tilton, Lauren and Walsh, Melanie}, editor = {{---}}, year = {2025}, month = sep, journal = {Anthology of Computers and the Humanities}, ach = {https://doi.org/10.63744/HHsQG7hNWyxG}, volume = {1}, pages = {1--5}, doi = {10.63744/HHsQG7hNWyxG}, urldate = {2025-11-05}, langid = {english} } -
 The Sneaky Gender Bias in Picture Books: Animal CharactersMelanie WalshPublishers Weekly, Aug 2025
The Sneaky Gender Bias in Picture Books: Animal CharactersMelanie WalshPublishers Weekly, Aug 2025 -
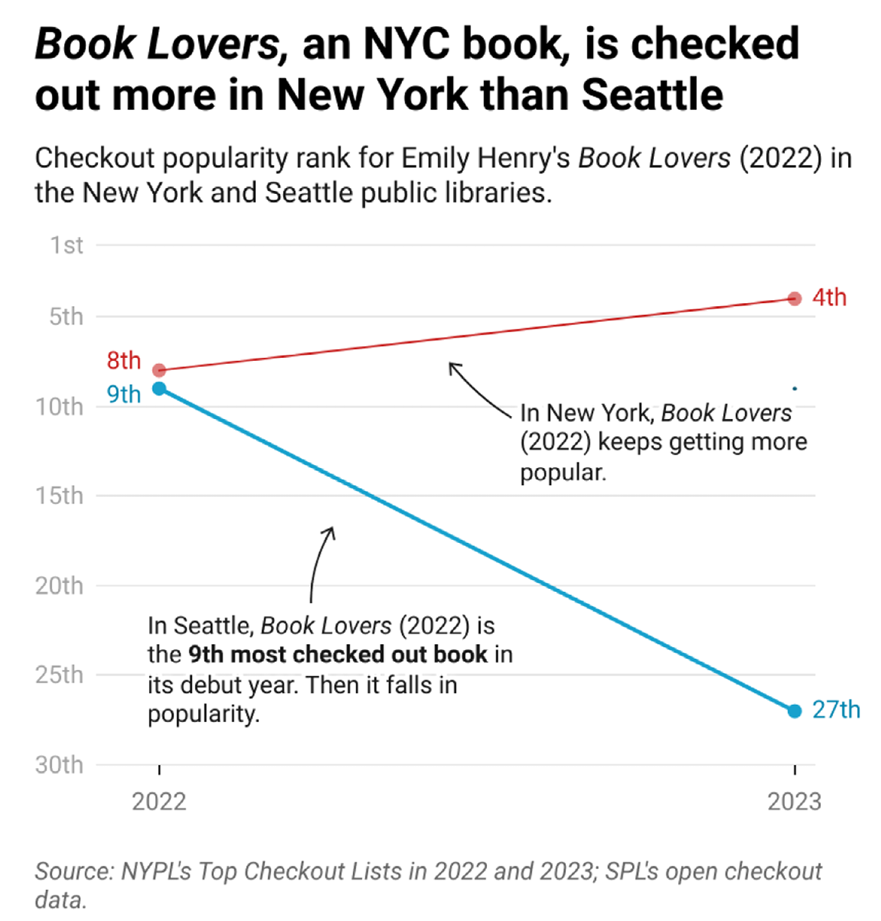 Seattle Public Library’s Open Checkout Data: What Can It Tell Us About Readers and Book Popularity More Broadly?Neel Gupta, David Christensen, and Melanie WalshJournal of Open Humanities Data, Aug 2025
Seattle Public Library’s Open Checkout Data: What Can It Tell Us About Readers and Book Popularity More Broadly?Neel Gupta, David Christensen, and Melanie WalshJournal of Open Humanities Data, Aug 2025The Seattle Public Library (SPL) publishes anonymized, open-access checkout data for every item in its collection, dating from 2005 to the present. To our knowledge, it is the only U.S. library to release checkout data by title with this level of temporal detail: one dataset records exact timestamps for print book checkouts, while another provides monthly aggregates across all formats (e.g., ebooks, audiobooks, print books). Because U.S. book sales data is largely inaccessible outside the publishing industry, SPL’s open checkout data offers a rare and valuable alternative. But how well does it generalize beyond Seattle? Does it reflect book sales? And what can it tell us about readers more broadly? In this paper, we introduce SPL’s checkout data and evaluate its potential for humanistic and literary research. We specifically assess how well it: (1) corresponds with book sales, (2) and extrapolates to library checkout patterns elsewhere nationally. First, we compare SPL data against publishing revenue reports and prior research with access to sales figures. We find that SPL patrons embrace digital books more than general consumers, but the overall distribution of checkouts resembles broader book sales patterns. Second, we compare SPL’s most checked out books per year to the New York Public Library’s annual top 10 lists. We find general overlap, but also distinct regional preferences, suggesting geographic extrapolation should be approached with caution. We conclude that SPL’s checkout data provides a rare window into library circulation and reading habits, with granular, time-series insights. However, its generalizability—particularly across regions and in relation to book sales—remains uncertain.
@article{guptaSeattlePublicLibrarys2025, title = {Seattle Public Library's Open Checkout Data: What Can It Tell Us About Readers and Book Popularity More Broadly?}, author = {Gupta, Neel and Christensen, David and Walsh, Melanie}, year = {2025}, month = aug, journal = {Journal of Open Humanities Data}, volume = {11}, number = {1}, issn = {2059-481X}, doi = {10.5334/johd.332}, johd = {https://doi.org/10.5334/johd.332}, urldate = {2025-09-10}, langid = {american}, } -
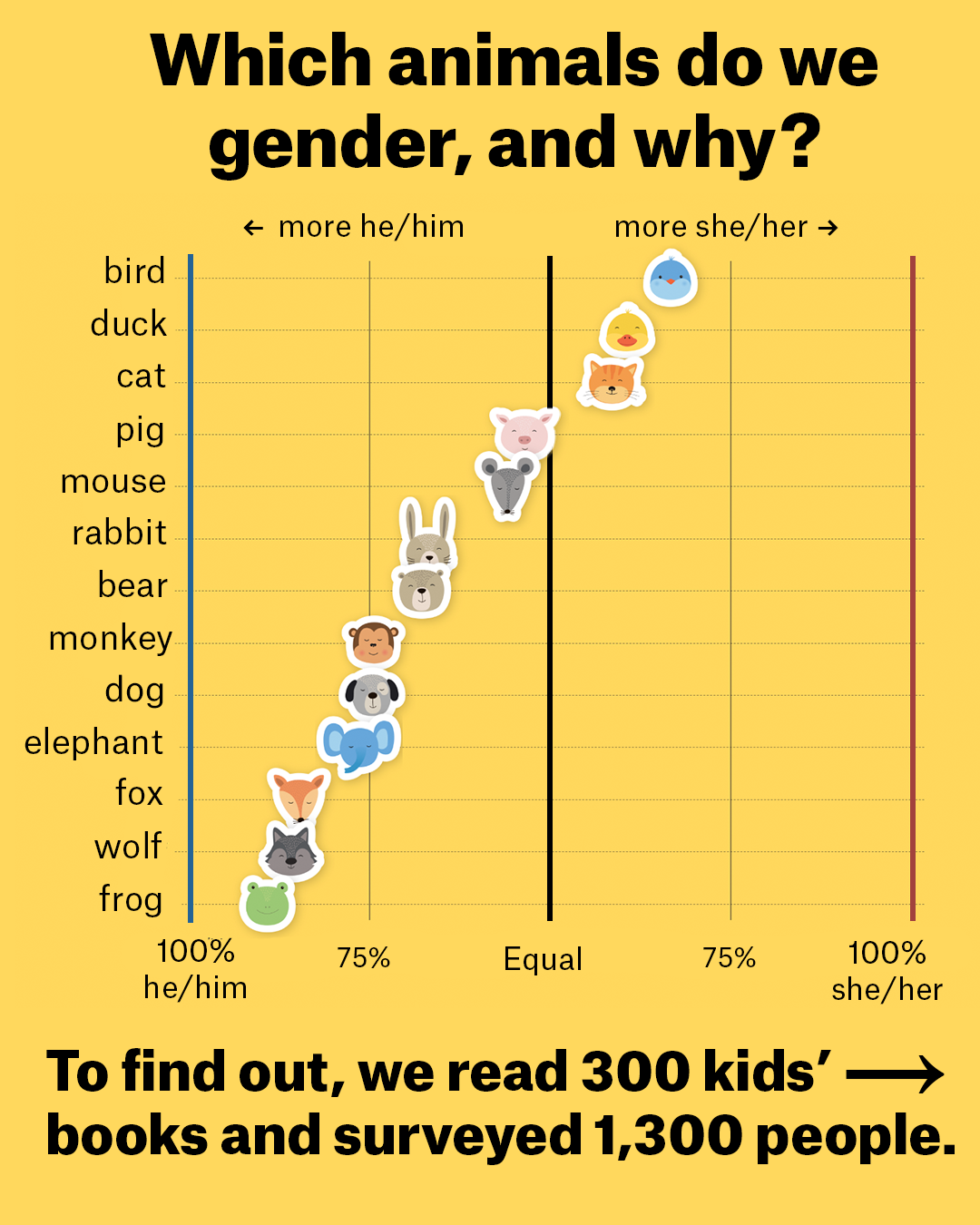 Bears Will Be BoysMelanie Walsh, Russell Samora, Michelle Pera-McGhee, and Jan DiehmThe Pudding, Jul 2025
Bears Will Be BoysMelanie Walsh, Russell Samora, Michelle Pera-McGhee, and Jan DiehmThe Pudding, Jul 2025In this data essay, we explore animal gender by analyzing 300 children’s books surveying 1,300+ people. Why are frogs always boys? Are ladybugs "ladies" in all languages?
@article{Walsh_Pudding_2025, title = {Bears Will Be Boys}, pudding = {https://pudding.cool/2025/07/kids-books/}, journal = {The Pudding}, author = {Walsh, Melanie and Samora, Russell and Pera-McGhee, Michelle and Diehm, Jan}, year = {2025}, month = jul, bibtex_show = true } -
 Not With a Bang But a Tweet: Democracy, Culture Wars, and the Memeification of T.S. EliotMelanie Walsh, and Anna PreusJun 2025Amherst College Press
Not With a Bang But a Tweet: Democracy, Culture Wars, and the Memeification of T.S. EliotMelanie Walsh, and Anna PreusJun 2025Amherst College PressModernist poet T.S. Eliot concluded his 1925 poem "The Hollow Men" with the iconic lines: "This is the way the world ends / Not with a bang but a whimper." When Eliot died in 1965, the New York Times claimed in his obituary that these lines were “probably the most quoted lines of any 20th-century poet writing in English.” They may be among the most memed lines, as well. Through a computational analysis of Twitter data, we have found that at least 350,000 tweets have referenced or remixed Eliot’s lines since the beginning of Twitter’s history in 2006. While references to the poem vary widely, we focus on two prominent political usages of the phrase — cases where Twitter users invoke it to warn about the state of modern democracy, often from the left side of the political spectrum, and cases where they use the phrase to critique political correctness and “cancel culture” or to mock people for non-normatized aspects of their identities, often from the right side of the political spectrum. Though some of the tweets cite Eliot directly, most do not, and in many cases the phrase almost seems to be moving from an authored quotation into a common idiom or turn-of-phrase. Linguistics experts increasingly refer to this kind of construction as a “snowclone” —a fixed phrasal template, often with a culturally salient source (e.g., a quotation from a book, TV show, or movie), that has “one or more variable slots” into which users insert various “lexical substitutions" (Hartmann and Ungerer).
@inbook{Walsh_Preus_2025, title = {Not {{With}} a {{Bang But}} a {{Tweet}}: {{Democracy}}, {{Culture Wars}}, and the {{Memeification}} of {{T}}.{{S}}. {{Eliot}}}, booktitle = {Expressive {{Networks}}: {{Poetry}} and {{Platform Cultures}}}, author = {Walsh, Melanie and Preus, Anna}, editor = {Kilbane, Matthew}, year = {2025}, month = jun, publisher = {Amherst College Press}, note = {Amherst College Press}, doi = {10.3998/mpub.14525819}, expressive = {https://www.fulcrum.org/epubs/q524jr70t?locale=en#/6/22[ch10]!/4/2[c5]/2/2/2[p63]/1:0}, data = {https://socialmediaarchive.org/record/60}, } -
 Algorithms in the Stacks: Investigating Automated, For-Profit Diversity Audits in Public LibrariesMelanie Walsh, Connor Franklin Rey, Chang Ge, Tina Nowak, and Sabina TomkinsIn FAccT (ACM Conference on Fairness, Accountability, and Transparency), Jun 2025
Algorithms in the Stacks: Investigating Automated, For-Profit Diversity Audits in Public LibrariesMelanie Walsh, Connor Franklin Rey, Chang Ge, Tina Nowak, and Sabina TomkinsIn FAccT (ACM Conference on Fairness, Accountability, and Transparency), Jun 2025Algorithmic systems are increasingly being adopted by cultural heritage institutions like libraries. In this study, we investigate U.S. public libraries’ adoption of one specific automated tool – automated collection diversity audits – which we see as an illuminating case study for broader trends. Typically developed and sold by commercial book distributors, automated diversity audits aim to evaluate how well library collections reflect demographic and thematic diversity. We investigate how these audits function, whether library workers find them useful, and what is at stake when sensitive, normative decisions about representation are outsourced to automated commercial systems. Our analysis draws on an anonymous survey of U.S. public librarians (n=99), interviews with 14 librarians, a sample of purchasing records, and vendor documentation. We find that many library workers view these tools as convenient, time-saving solutions for assessing and diversifying collections under real and increasing constraints. Yet at the same time, the audits often flatten complex identities into standardized categories, fail to reflect local community needs, and further entrench libraries’ infrastructural dependence on vendors. We conclude with recommendations for improving collection diversity audits and reflect on the broader implications for public libraries operating at the intersection of AI adoption, escalating anti-DEI backlash, and politically motivated defunding.
@inproceedings{walshAlgorithmsStacksInvestigating2025, title = {Algorithms in the {{Stacks}}: {{Investigating}} Automated, For-Profit Diversity Audits in Public Libraries}, shorttitle = {Algorithms in the {{Stacks}}}, booktitle = {{{FAccT}} ({{ACM Conference}} on {{Fairness}}, {{Accountability}}, and {{Transparency}})}, author = {Walsh, Melanie and Rey, Connor Franklin and Ge, Chang and Nowak, Tina and Tomkins, Sabina}, year = {2025}, month = jun, doi = {10.1145/3715275.3732140}, } -
 Provocations from the Humanities for Generative AI Research (Pre-Print)Lauren Klein, Meredith Martin, André Brock, Maria Antoniak, Melanie Walsh, Jessica Marie Johnson, and 2 more authorsFeb 2025
Provocations from the Humanities for Generative AI Research (Pre-Print)Lauren Klein, Meredith Martin, André Brock, Maria Antoniak, Melanie Walsh, Jessica Marie Johnson, and 2 more authorsFeb 2025This paper presents a set of provocations for considering the uses, impact, and harms of generative AI from the perspective of humanities researchers. We provide a working definition of humanities research, summarize some of its most salient theories and methods, and apply these theories and methods to the current landscape of AI. Drawing from foundational work in critical data studies, along with relevant humanities scholarship, we elaborate eight claims with broad applicability to current conversations about generative AI: 1) Models make words, but people make meaning; 2) Generative AI requires an expanded definition of culture; 3) Generative AI can never be representative; 4) Bigger models are not always better models; 5) Not all training data is equivalent; 6) Openness is not an easy fix; 7) Limited access to compute enables corporate capture; and 8) AI universalism creates narrow human subjects. We conclude with a discussion of the importance of resisting the extraction of humanities research by computer science and related fields.
@article{kleinProvocationsHumanitiesGenerative2025, title = {Provocations from the {{Humanities}} for {{Generative AI Research}} (Pre-Print)}, author = {Klein, Lauren and Martin, Meredith and Brock, André and Antoniak, Maria and Walsh, Melanie and Johnson, Jessica Marie and Tilton, Lauren and Mimno, David}, date = {2025-02-26}, year = {2025}, month = feb, eprint = {2502.19190}, eprinttype = {arXiv}, eprintclass = {cs}, urldate = {2025-03-24}, pubstate = {prepublished}, keywords = {Computer Science - Artificial Intelligence,Computer Science - Computers and Society}, file = {/Users/melwalsh/Zotero/storage/SN7FMYBN/Klein et al. - 2025 - Provocations from the Humanities for Generative AI.pdf;/Users/melwalsh/Zotero/storage/2VMLXASY/2502.html} }
2024
-
 Does ChatGPT Have a Poetic Style?Melanie Walsh, Anna Preus, and Elizabeth GronskiIn Computational Humanities Research (CHR), Dec 2024arXiv:2410.15299
Does ChatGPT Have a Poetic Style?Melanie Walsh, Anna Preus, and Elizabeth GronskiIn Computational Humanities Research (CHR), Dec 2024arXiv:2410.15299Generating poetry has become a popular application of LLMs, perhaps especially of OpenAI’s widely-used chatbot ChatGPT. What kind of poet is ChatGPT? Does ChatGPT have its own poetic style? Can it successfully produce poems in different styles? To answer these questions, we prompt the GPT-3.5 and GPT-4 models to generate English-language poems in 24 different poetic forms and styles, about 40 different subjects, and in response to 3 different writing prompt templates. We then analyze the resulting 5.7k poems, comparing them to a sample of 3.7k poems from the Poetry Foundation and the Academy of American Poets. We find that the GPT models, especially GPT-4, can successfully produce poems in a range of both common and uncommon English-language forms in superficial yet noteworthy ways, such as by producing poems of appropriate lengths for sonnets (14 lines), villanelles (19 lines), and sestinas (39 lines). But the GPT models also exhibit their own distinct stylistic tendencies, both within and outside of these specific forms. Our results show that GPT poetry is much more constrained and uniform than human poetry, showing a strong penchant for rhyme, quatrains (4-line stanzas), iambic meter, first-person plural perspectives (we, us, our), and specific vocabulary like “heart,” “embrace,” “echo,” and “whisper.”
@inproceedings{Walsh_Preus_Gronski_2024, title = {Does ChatGPT Have a Poetic Style?}, doi = {10.48550/arXiv.2410.15299}, chr = {https://ceur-ws.org/Vol-3834/}, note = {arXiv:2410.15299}, number = {arXiv:2410.15299}, publisher = {arXiv}, author = {Walsh, Melanie and Preus, Anna and Gronski, Elizabeth}, year = {2024}, month = dec, booktitle = {Computational Humanities Research (CHR)} } -
 Sonnet or Not, Bot? Poetry Evaluation for Large Models and DatasetsMelanie Walsh, Maria Antoniak, and Anna PreusIn Findings of the Association for Computational Linguistics: EMNLP, Nov 2024
Sonnet or Not, Bot? Poetry Evaluation for Large Models and DatasetsMelanie Walsh, Maria Antoniak, and Anna PreusIn Findings of the Association for Computational Linguistics: EMNLP, Nov 2024Large language models (LLMs) can now generate and recognize poetry. But what do LLMs really know about poetry? We develop a task to evaluate how well LLMs recognize one aspect of English-language poetry—poetic form—which captures many different poetic features, including rhyme scheme, meter, and word or line repetition. By using a benchmark dataset of over 4.1k human expert-annotated poems, we show that state-of-the-art LLMs can successfully identify both common and uncommon fixed poetic forms—such as sonnets, sestinas, and pantoums—with surprisingly high accuracy. However, performance varies significantly by poetic form; the models struggle to identify unfixed poetic forms, especially those based on topic or visual features. We additionally measure how many poems from our benchmark dataset are present in popular pretraining datasets or memorized by GPT-4, finding that pretraining presence and memorization may improve performance on this task, but results are inconclusive. We release a benchmark evaluation dataset with 1.4k public domain poems and form annotations, results of memorization experiments and data audits, and code.
@inproceedings{Walsh_Antoniak_Preus_2024, title = {Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets}, abstractnote = {Large language models (LLMs) can now generate and recognize poetry. But what do LLMs really know about poetry? We develop a task to evaluate how well LLMs recognize one aspect of English-language poetry—poetic form—which captures many different poetic features, including rhyme scheme, meter, and word or line repetition. By using a benchmark dataset of over 4.1k human expert-annotated poems, we show that state-of-the-art LLMs can successfully identify both common and uncommon fixed poetic forms—such as sonnets, sestinas, and pantoums—with surprisingly high accuracy. However, performance varies significantly by poetic form; the models struggle to identify unfixed poetic forms, especially those based on topic or visual features. We additionally measure how many poems from our benchmark dataset are present in popular pretraining datasets or memorized by GPT-4, finding that pretraining presence and memorization may improve performance on this task, but results are inconclusive. We release a benchmark evaluation dataset with 1.4k public domain poems and form annotations, results of memorization experiments and data audits, and code.}, acl = {https://aclanthology.org/2024.findings-emnlp.914/}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP}, author = {Walsh, Melanie and Antoniak, Maria and Preus, Anna}, year = {2024}, month = nov, language = {en} } -
 The Afterlives of Shakespeare and Company in Online Social ReadershipMaria Antoniak, David Mimno, Rosamond Thalken, Melanie Walsh, Matthew Wilkens, and Gregory YauneyModernism/modernity and Journal of Cultural Analytics, Jan 2024Modernism/modernity Journal of Cultural Analytics arXiv PDF Interactive Plots Code & Data Copy Bibtex Citation Read the Abstract
The Afterlives of Shakespeare and Company in Online Social ReadershipMaria Antoniak, David Mimno, Rosamond Thalken, Melanie Walsh, Matthew Wilkens, and Gregory YauneyModernism/modernity and Journal of Cultural Analytics, Jan 2024Modernism/modernity Journal of Cultural Analytics arXiv PDF Interactive Plots Code & Data Copy Bibtex Citation Read the AbstractThe growth of social reading platforms such as Goodreads and LibraryThing enables us to analyze reading activity at very large scale and in remarkable detail. But twenty-first century systems give us a perspective only on contemporary readers. Meanwhile, the digitization of the lending library records of Shakespeare and Company provides a window into the reading activity of an earlier, smaller community in interwar Paris. In this article, we explore the extent to which we can make comparisons between the Shakespeare and Company and Goodreads communities. By quantifying similarities and differences, we can identify patterns in how works have risen or fallen in popularity across these datasets. We can also measure differences in how works are received by measuring similarities and differences in co-reading patterns. Finally, by examining the complete networks of co-readership, we can observe changes in the overall structures of literary reception.
@article{Antoniak_Mimno_Thalken_Walsh_Wilkens_Yauney_2024, title = {The Afterlives of Shakespeare and Company in Online Social Readership}, url = {http://arxiv.org/abs/2401.07340}, modernism = {https://modernismmodernity.org/forums/posts/antoniak-etal-afterlives-shakespeare-co-online-social-readership}, abstractnote = {The growth of social reading platforms such as Goodreads and LibraryThing enables us to analyze reading activity at very large scale and in remarkable detail. But twenty-first century systems give us a perspective only on contemporary readers. Meanwhile, the digitization of the lending library records of Shakespeare and Company provides a window into the reading activity of an earlier, smaller community in interwar Paris. In this article, we explore the extent to which we can make comparisons between the Shakespeare and Company and Goodreads communities. By quantifying similarities and differences, we can identify patterns in how works have risen or fallen in popularity across these datasets. We can also measure differences in how works are received by measuring similarities and differences in co-reading patterns. Finally, by examining the complete networks of co-readership, we can observe changes in the overall structures of literary reception.}, number = {arXiv:2401.07340}, journal = {Modernism/modernity and Journal of Cultural Analytics}, publisher = {Johns Hopkins University Press}, author = {Antoniak, Maria and Mimno, David and Thalken, Rosamond and Walsh, Melanie and Wilkens, Matthew and Yauney, Gregory}, year = {2024}, month = jan }
2023
-
 Riveter: Measuring Power and Social Dynamics Between EntitiesMaria Antoniak, Anjalie Field, Jimin Mun, Melanie Walsh, Lauren F. Klein, and Maarten SapIn Association for Computational Linguistics (ACL), Jan 2023arXiv:2312.09536 [cs]
Riveter: Measuring Power and Social Dynamics Between EntitiesMaria Antoniak, Anjalie Field, Jimin Mun, Melanie Walsh, Lauren F. Klein, and Maarten SapIn Association for Computational Linguistics (ACL), Jan 2023arXiv:2312.09536 [cs]Riveter provides a complete easy-to-use pipeline for analyzing verb connotations associated with entities in text corpora. We prepopulate the package with connotation frames of sentiment, power, and agency, which have demonstrated usefulness for capturing social phenomena, such as gender bias, in a broad range of corpora. For decades, lexical frameworks have been foundational tools in computational social science, digital humanities, and natural language processing, facilitating multifaceted analysis of text corpora. But working with verb-centric lexica specifically requires natural language processing skills, reducing their accessibility to other researchers. By organizing the language processing pipeline, providing complete lexicon scores and visualizations for all entities in a corpus, and providing functionality for users to target specific research questions, Riveter greatly improves the accessibility of verb lexica and can facilitate a broad range of future research.
@inproceedings{Antoniak_Field_Mun_Walsh_Klein_Sap_2023, title = {Riveter: Measuring Power and Social Dynamics Between Entities}, url = {http://arxiv.org/abs/2312.09536}, doi = {10.18653/v1/2023.acl-demo.36}, acl = {https://aclanthology.org/2023.acl-demo.36/}, abstractnote = {Riveter provides a complete easy-to-use pipeline for analyzing verb connotations associated with entities in text corpora. We prepopulate the package with connotation frames of sentiment, power, and agency, which have demonstrated usefulness for capturing social phenomena, such as gender bias, in a broad range of corpora. For decades, lexical frameworks have been foundational tools in computational social science, digital humanities, and natural language processing, facilitating multifaceted analysis of text corpora. But working with verb-centric lexica specifically requires natural language processing skills, reducing their accessibility to other researchers. By organizing the language processing pipeline, providing complete lexicon scores and visualizations for all entities in a corpus, and providing functionality for users to target specific research questions, Riveter greatly improves the accessibility of verb lexica and can facilitate a broad range of future research.}, note = {arXiv:2312.09536 [cs]}, booktitle = {Association for Computational Linguistics (ACL)}, author = {Antoniak, Maria and Field, Anjalie and Mun, Jimin and Walsh, Melanie and Klein, Lauren F. and Sap, Maarten}, year = {2023}, pages = {377–388} } -
 The Challenges and Possibilities of Social Media Data: New Directions in Literary Studies and the Digital HumanitiesMelanie WalshJan 2023publisher: U of Minnesota Press
The Challenges and Possibilities of Social Media Data: New Directions in Literary Studies and the Digital HumanitiesMelanie WalshJan 2023publisher: U of Minnesota Press@inbook{Walsh_2023, title = {The Challenges and Possibilities of Social Media Data: New Directions in Literary Studies and the Digital Humanities}, url = {https://dhdebates.gc.cuny.edu/read/f3f87448-138c-4d19-8ff8-b06acf40ddd1/section/a57b98ab-0f10-45d0-b205-3e563aab7ea8#ch18}, note = {publisher: U of Minnesota Press}, booktitle = {Debates in the Digital Humanities 2023}, publisher = {University of Minnesota Press}, author = {Walsh, Melanie}, year = {2023} }
2022
-
 Where is all the book data?Melanie WalshPublic Books, Jan 2022🎙️I spoke about this essay with Australian radio ABC.🎙️
Where is all the book data?Melanie WalshPublic Books, Jan 2022🎙️I spoke about this essay with Australian radio ABC.🎙️
2021
-
 Tags, Borders, and Catalogs: Social Re-Working of Genre on LibraryThingMaria Antoniak, Melanie Walsh, and David MimnoCSCW, Apr 2021
Tags, Borders, and Catalogs: Social Re-Working of Genre on LibraryThingMaria Antoniak, Melanie Walsh, and David MimnoCSCW, Apr 2021Through a computational reading of the online book reviewing community LibraryThing, we examine the dynamics of a collaborative tagging system and learn how its users refine and redefine literary genres. LibraryThing tags are overlapping and multi-dimensional, created in a shared space by thousands of users, including readers, bookstore owners, and librarians. A common understanding of genre is that it relates to the content of books, but this resource allows us to view genre as an intersection of user communities and reader values and interests. We explore different methods of computational genre measurement within the open space of user-created tags. We measure overlap between books, tags, and users, and we also measure the homogeneity of communities associated with genre tags and correlate this homogeneity with reviewing behavior.Finally, by analyzing the text of reviews, we identify the thematic signatures of genres on LibraryThing, revealing similarities and differences between them. These measurements are intended to elucidate the genre conceptions of the users, not, as in prior work, to normalize the tags or enforce a hierarchy. We find that LibraryThing users make sense of genre through a variety of values and expectations, many of which fall outside common definitions and understandings of genre.
@article{Antoniak_Walsh_Mimno_2021, title = {Tags, Borders, and Catalogs: Social Re-Working of Genre on LibraryThing}, volume = {5}, issn = {2573-0142}, doi = {10.1145/3449103}, abstractnote = {Through a computational reading of the online book reviewing community LibraryThing, we examine the dynamics of a collaborative tagging system and learn how its users refine and redefine literary genres. LibraryThing tags are overlapping and multi-dimensional, created in a shared space by thousands of users, including readers, bookstore owners, and librarians. A common understanding of genre is that it relates to the content of books, but this resource allows us to view genre as an intersection of user communities and reader values and interests. We explore different methods of computational genre measurement within the open space of user-created tags. We measure overlap between books, tags, and users, and we also measure the homogeneity of communities associated with genre tags and correlate this homogeneity with reviewing behavior.Finally, by analyzing the text of reviews, we identify the thematic signatures of genres on LibraryThing, revealing similarities and differences between them. These measurements are intended to elucidate the genre conceptions of the users, not, as in prior work, to normalize the tags or enforce a hierarchy. We find that LibraryThing users make sense of genre through a variety of values and expectations, many of which fall outside common definitions and understandings of genre.}, url = {https://dl.acm.org/doi/10.1145/3449103}, number = {CSCW}, journal = {CSCW}, author = {Antoniak, Maria and Walsh, Melanie and Mimno, David}, year = {2021}, month = apr, pages = {1–29}, language = {en} } -
 The Goodreads “Classics”: A Computational Study of Readers, Amazon, and Crowdsourced Amateur CriticismMelanie Walsh, and Maria AntoniakPost45 and Journal of Cultural Analytics, Apr 2021Post45 Journal of Cultural Analytics PDF Interactive Plots Code & Data Goodreads Scraper Copy Bibtex Citation
The Goodreads “Classics”: A Computational Study of Readers, Amazon, and Crowdsourced Amateur CriticismMelanie Walsh, and Maria AntoniakPost45 and Journal of Cultural Analytics, Apr 2021Post45 Journal of Cultural Analytics PDF Interactive Plots Code & Data Goodreads Scraper Copy Bibtex Citation@article{Walsh_Antoniak_2021, title = {The Goodreads “Classics”: A Computational Study of Readers, Amazon, and Crowdsourced Amateur Criticism}, volume = {6}, url = {https://culturalanalytics.org/article/22221.pdf}, number = {2}, journal = {Post45 and Journal of Cultural Analytics}, author = {Walsh, Melanie and Antoniak, Maria}, year = {2021}, bibtex_show = true } -
 Introduction to Cultural Analytics & PythonMelanie WalshApr 2021🏆 Voted Best Digital Humanities Training Material in 2021 🏆
Introduction to Cultural Analytics & PythonMelanie WalshApr 2021🏆 Voted Best Digital Humanities Training Material in 2021 🏆Voted Best Digital Humanities Training Material in 2021
@book{Walsh_2021, title = {Introduction to Cultural Analytics & Python}, url = {https://melaniewalsh.github.io/Intro-Cultural-Analytics}, publisher = {Jupyter Book}, author = {Walsh, Melanie}, year = {2021} }
2018
-
 Tweets of a Native Son: The Quotation and Recirculation of James Baldwin from Black Power to #BlackLivesMatterMelanie WalshAmerican Quarterly, Apr 2018
Tweets of a Native Son: The Quotation and Recirculation of James Baldwin from Black Power to #BlackLivesMatterMelanie WalshAmerican Quarterly, Apr 2018@article{Walsh_2018, title = {Tweets of a Native Son: The Quotation and Recirculation of James Baldwin from Black Power to #BlackLivesMatter}, volume = {70}, number = {3}, journal = {American Quarterly}, publisher = {Johns Hopkins University Press}, author = {Walsh, Melanie}, year = {2018}, pages = {531–559}, }