Part 2: Building the “Tweets of a Native Son” Archive (jq and regular expressions)
In Part 1, I explained how I “hydrated” 17 million tweets that mentioned “Ferguson” from August and November 2014 by using twarc and how I generated summaries for these collections (# of tweets and users, top hashtags, top URLs, top image URLS, etc.) using twarc-report. But how and where does James Baldwin fit into the picture?
In this post, I’m going to talk about what Twitter metadata looks like (spoiler alert: it’s pretty kooky) and how I reshaped the metadata to find only tweets that mentioned James Baldwin by using jq, a command-line utility for filtering JSON data.
Twitter metadata is wild. Every single tweet carries with it an enormous amount of information. Even a tweet as seemingly meaningless as “:poop:” carries with it not just the “text” (:poop:) of the tweet but also many other metadata fields such as:
- when the tweet was created
- how many times the tweet has been favorited or retweeted
- what language the tweet was written in
- which user wrote the tweet
- when the user created his or her account
- the user’s profile description and profile picture and profile background color
- the user’s location
- how many people follow the user
- how many people the user follows
- how many tweets the user has ever favorited
- how many tweets the user has ever sent
…and much, much more.1
Here’s just a glimpse of a single tweet from the August archive, which goes on for 96 lines:
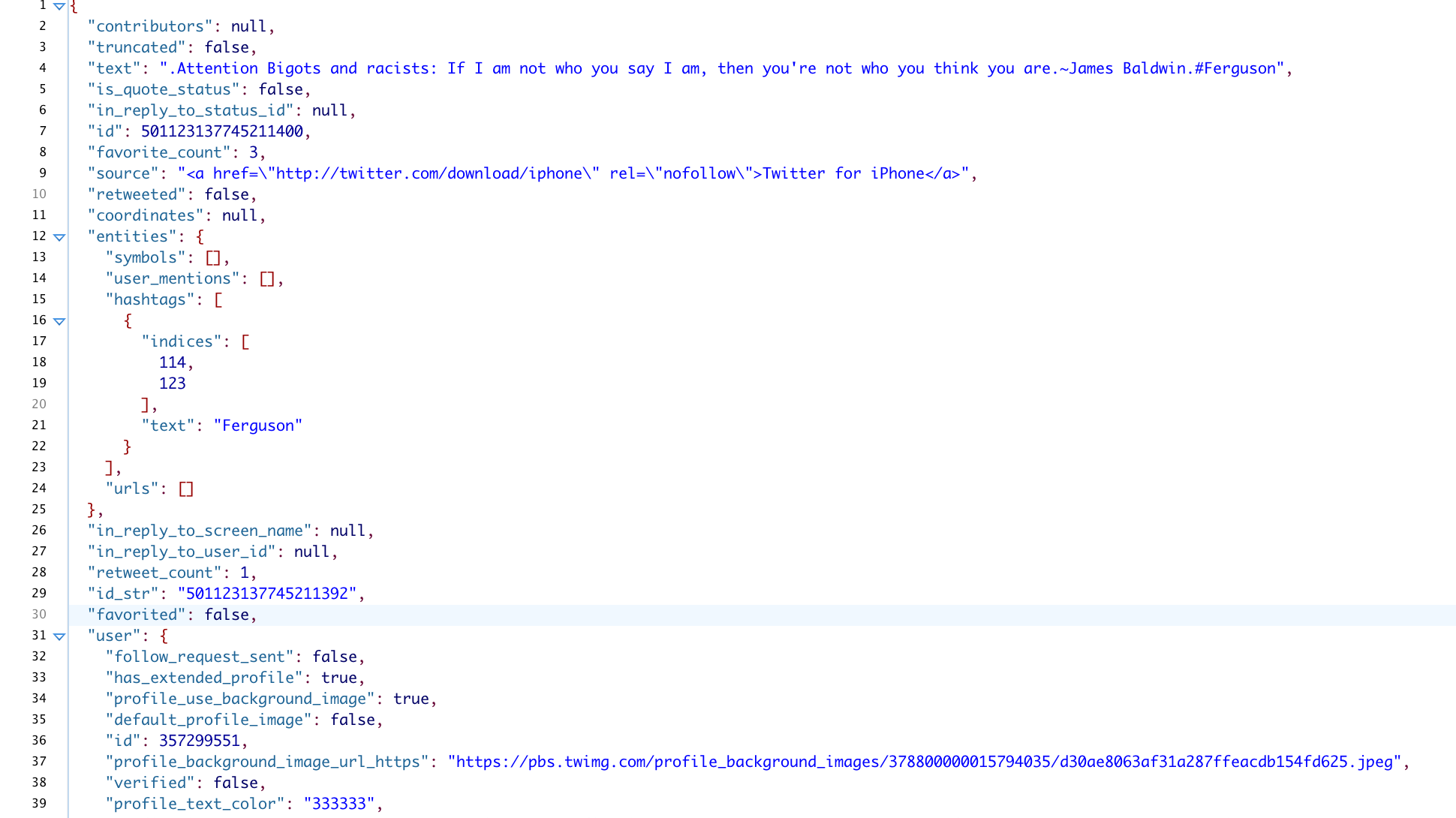
As a tweet gets more complex—a reply to another user with a hashtag and a URL or a retweet with an image—the metadata gets even bigger and richer.
This richness makes the metadata wonderful for research purposes, allowing us to investigate all kinds of questions, but it also makes the data difficult to work with. If we want to extract just the tweets that mention James Baldwin, the nested structure of the JSON data (which you can learn more about here) makes that a tricky task.
This is where jq comes in, a command-line utility for reshaping JSON data. With jq, you can extract information from particular fields (“text,” “coordinates,” retweet_count,” etc.) even when those fields are nested within other fields. You can even output the JSON data to a flat CSV file.2 For my purposes, I extracted only the tweets that mentioned James Baldwin by performing the filter operation select() on the .text field of the tweets, combined with a regular expressions string match for “James Baldwin” test("James Baldwin"):
jq -c "select(.text | test(\"James Baldwin\"))" tweets.json > jamesbaldwin.json
This operation returned 1,697 tweets that mentioned “James Baldwin” from the August Ferguson tweet collection. But that’s only when “James Baldwin” was spelled correctly with proper capitalization and spacing. So I decided to expand the search to collect other variations of his name without regard for capitalization and spacing, as well as permitting just a first initial and even misspellings that may have accidentally dropped the “d” from his name (#JamesBaldwin; J BALDWIN; james baldwin, James Balwin, etc.) :
jq -c "select(.text | test(\"J(ames|) ?Bald?win\";\"i\"))" tweets.json > jamesbaldwin.json
This operation returned an increased 1,839 tweets from the August collection and 1,393 tweets from the November collection. I experimented with an even more expansive search for simply “Baldwin,” which returned 3,410 tweets, but too many of them referenced a “Baldwin” not related to the literary James of interest, picking up instead on users’ last names, the actor Alec Baldwin, etc.
These 3,232 tweets from August and November quantitatively confirm scholars’ claims—among them, Eddie S. Glaude and William J. Maxwell—that Baldwin is and was a leading literary voice in the burgeoning #BlackLivesMatter movement, since it proves that James Baldwin was being invoked and talked about on Twitter in the aftermath of Ferguson.
Yet the James Baldwin conversation represents less than one-percent of the total Twitter conversation in either dataset, which serves as a tempering reminder that the scholarly sense of what is dominant in the larger cultural conversation may be skewed by scholarly newsfeeds. These numbers may even seem small enough to dismiss the case for Baldwin’s prominence on Twitter. But when cross-compared to other prominent black writers, Baldwin is far and away the most invoked. The words “James Baldwin” appear more in the August collection than “Claudia Rankine” (416), “Langston Hughes” (281), “Assata Shakur” (130), “Ta-Nehisi Coates” (129), “Toni Morrison” (72), “Teju Cole” (55), “Richard Wright” (50), “Ralph Ellison” (49), and “Amiri Baraka” (10) combined.
But why? Why does Baldwin appear so much more frequently than other black writers? What about his style, insights, or legacy resonates in this particular historical moment and on this particular platform?
These are the literary questions that I will seek to answer in future posts through close-reading and further investigation of the data. But for now, I’ll just share an overview of the Ferguson-Baldwin data produced using some twarc utilities and twarc-report. Check out the most popular retweets, hashtags, URLs, and image URLs below.
August Baldwin Tweet Archive
| Tweets: | 1,839 | ||
| Users: | 1,753 | ||
| Has Hashtag: | 1,169 (63.57%) | ||
| Hashtags: | 115 | ||
| Has URL: | 609 (33.12%) | ||
| URLs: | 166 | ||
| Has Image URL: | 47 (2.56%) | ||
| Image URLs: | 18 | ||
| Retweets: | 1,327 (72.16%) | ||
| Geo: | 11 (0.60%) | ||
| Earliest Tweet: 2014-08-11 04:16:44 UTC |
"To be a Negro in this country and to be relatively conscious is to be in a rage almost all the time. ” ― James Baldwin #Ferguson
— Renaissance Man (@cjfluker) August 11, 2014
| Latest Tweet: | 2014-08-27 12:46:48 UTC |
'This Fight Begins In The Heart': Reading James Baldwin As Ferguson Seethes : NPR http://t.co/iLyNSrgwFZ
— AC De Lion (@anydel) August 27, 2014
| Total Duration: | 16 days, 8:30:04 |
Top 10 Retweets:
"To be Black and conscious in America is to be in a constant state of rage." - James Baldwin #Ferguson
— zellie (@zellieimani) August 14, 2014
"To be a Negro in this country and to be relatively conscious is to be in a rage almost all the time." —James Baldwin #Ferguson
— Crystal Kayiza (@c_kayiza) August 11, 2014
My new article on #Ferguson, #MikeBrown, systemic racism and James Baldwin; if of interest, please share.http://t.co/DxhX3gCnnF
— Musa Okwonga (@Okwonga) August 14, 2014
if you're following #Ferguson, watch this essential #JamesBaldwin testimony in June 1963: https://t.co/EVTTXgp82s
— Jose Antonio Vargas (@joseiswriting) August 18, 2014
"This fight begins in the heart": @LailaLalami on reading James Baldwin as Ferguson seethes: http://t.co/pwErhUga3Z
— NPR Books (@nprbooks) August 19, 2014
‘Not everything that is faced can be changed, but nothing can be changed until it is faced.’ - James Baldwin #FERGUSON
— sandrine. (@drineee) August 25, 2014
http://t.co/mFvaZuMAIw Teju Cole's beautiful & lacerating piece on James Baldwin, the "black body" & the white gaze, #Ferguson & beyond.
— Joyce Carol Oates (@JoyceCarolOates) August 23, 2014
A quote from James Baldwin in a PSA on #Ferguson that aired during last night’s #VMAs WATCH: http://t.co/X0Q7Zs2z3y pic.twitter.com/VyMthSXw6c
— SPLC (@splcenter) August 25, 2014
"But black people raise their children as a rehearsal for danger.” -James Baldwin #Ferguson
— Salamishah Tillet (@salamishah) August 20, 2014
"White people think that childhood is a rehearsal for success. White people think of themselves as safe." -James Baldwin #Ferguson
— Salamishah Tillet (@salamishah) August 20, 2014
| Top Hashtags: | |||
| 1. ferguson | 1,093 | ||
| 2. jamesbaldwin | 122 | ||
| 3. vmas | 84 | ||
| 4. lookdifferent | 61 | ||
| 5. mikebrown | 53 | ||
| 6. nmos14 | 28 | ||
| 7. vmawards | 17 | ||
| 8. books | 15 | ||
| 9. vmas2014 | 15 | ||
| 10. moralmonday | 15 | ||
| Top URLs: | |||
| 1. https://www.youtube.com/watch?v=kXwVnYGJ_Cw | 73 | ||
| 2. http://www.newyorker.com/books/page-turner/black-body-re-reading-james-baldwins-stranger-village | 61 | ||
| 3. http://n.pr/1lfM1Ej | 59 | ||
| 4. http://sp.lc/VOarbH | 49 | ||
| 5. http://n.pr/1rstgvg | 33 | ||
| 6. http://wp.me/p4Rl2x-aCX | 27 | ||
| 7. http://esqm.ag/6015W6MW | 23 | ||
| 8. https://twitter.com/drgoddess/status/503726211621982208 | 15 | ||
| 9. http://j.mp/1p3a2t0 | 15 | ||
| 10. http://n.pr/VFtghp | 11 | ||
| Top Image URLs: | |||
1.  |
15 | ||
2.  |
6 | ||
3.  |
5 | ||
4.  |
4 | ||
5.  |
2 | ||
6.  |
2 | ||
7.  |
2 | ||
8.  |
1 | ||
9.  |
1 | ||
10.  |
1 |
November Baldwin Archive
| Tweets: | 1,393 | ||
| Users: | 1,231 | ||
| Has Hashtag: | 952 (68.34%) | ||
| Hashtags: | 113 | ||
| Has URL: | 388 (27.85%) | ||
| URLs: | 203 | ||
| Has Image URL: | 213 (15.29%) | ||
| Image URLs: | 47 | ||
| Retweets: | 987 (70.85%) | ||
| Geo: | 11 (0.79%) | ||
| Earliest Tweet: | 2014-11-12 05:38:56 UTC |
"It is certain, in any case, that ignorance, allied with power, is the most ferocious enemy justice can have." ~ James Baldwin~ || #Ferguson
— Dante Boykin (@DanteB4u) November 12, 2014
| Latest Tweet (Retweet): | 2014-12-10 04:08:08 UTC |
"If I love you, I have to make you conscious of the things you do not see." James Baldwin #icantbreathe #ferguson https://t.co/OKyGqNu5HX
— Laurenellen McCann!! (@elle_mccann) December 9, 2014
| Total Duration: | 27 days, 22:29:12 |
Top 10 Retweets:
James Baldwin quoted for Mike Brown. Union Square #Ferguson demo pic.twitter.com/u23WRicZR8
— Molly Crabapple (@mollycrabapple) November 25, 2014
"To be black in America is to be in a constant state of rage."
— Courtney Thornton (@courteroy_) November 25, 2014
-James Baldwin #MikeBrown #FergusonTheRoot #Ferguson
We live in "a civilization which has always glorified violence--unless the Negro had the gun."--James Baldwin circa 1963 #Ferguson
— Jose Antonio Vargas (@joseiswriting) November 25, 2014
"To be black and conscious in america is a constant state of rage" - James Baldwin#noblackjusticenoblackfriday#Ferguson
— Gbenga Akinnagbe (@GbengaAkinnagbe) November 25, 2014
My article on #Ferguson and #MikeBrown, with an important quote from James Baldwin. If of interest, please share. http://t.co/S5DsNyJAmG
— Musa Okwonga (@Okwonga) November 25, 2014
James Baldwin's prophetic words in 1960#Ferguson #BlackLivesMatter #FergusionDecision pic.twitter.com/G4KX6bRdfF
— Rahiel Tesfamariam (@RahielT) November 25, 2014
"To be a Negro in this country and to be relatively conscious is to be in a rage almost all the time." —James Baldwin #Ferguson
— Crystal Kayiza (@c_kayiza) August 11, 2014
James Baldwin: "The law is meant to be my servant and not my master, still less my torturer and my murderer." #Ferguson
— Nikhil Goyal (@nikhilgoya_l) November 25, 2014
“To be a Negro in this country and to be relatively conscious is to be in a rage almost all the time. ” – James Baldwin #Ferguson
— Yasiel Plug (@Ketchcast) November 25, 2014
"To be a Negro in this country and to be relatively conscious is to be in a rage almost all the time." - James Baldwin #Ferguson
— BlackHistoryStudies (@BlkHistStudies) November 27, 2014
| Top Hashtags: | |||
| 1. ferguson | 836 | ||
| 2. mikebrown | 196 | ||
| 3. blacklivesmatter | 174 | ||
| 4. jamesbaldwin | 104 | ||
| 5. noblackjusticenoblackfriday | 48 | ||
| 6. fergusiondecision | 45 | ||
| 7. icantbreathe | 34 | ||
| 8. fergusontheroot | 23 | ||
| 9. hiphoped | 22 | ||
| 10. standup | 20 | ||
| Top URLs: | |||
| 1. http://Advocate.com | 54 | ||
| 2. http://www.cbc.ca/thesundayedition/features/2014/11/30/post-11/ | 33 | ||
| 3. http://esqm.ag/6013t1KF | 23 | ||
| 4. http://shar.es/1XEN2s | 18 | ||
| 5. http://www.advocate.com/politics/2014/11/25/5-james-baldwin-quotes-foreshadowed-ferguson | 18 | ||
| 6. http://www.agos.com.tr/tr/yazi/9893/fergusondan-yuksekovaya-james-baldwinin-ruhuyla | 16 | ||
| 7. http://www.neontommy.com/news/2014/12/ferguson-and-blacklivesmatter-illustrate-how-james-baldwin-s-words-continue-resonate-mo | 11 | ||
| 8. http://bit.ly/1yTCKna | 11 | ||
| 9. http://bit.ly/1B9TCdI | 10 | ||
| 10. http://www.newstatesman.com/politics/2014/08/amid-tear-gas-and-arrests-reporters-ferguson-we-must-not-lose-sight-mike-brown | 9 | ||
| Top Image URLs: | |||
1.  |
45 | ||
2.  |
44 | ||
3.  |
23 | ||
4.  |
19 | ||
5.  |
9 | ||
6.  |
8 | ||
7.  |
7 | ||
8.  |
5 | ||
9.  |
4 | ||
10.  |
4 |
-
If you’re interested in finding out more about the structure of Twitter metadata, check out Twitter’s documentation here. ↩
-
For a full jq tutorial, I recommend Matthew Lincoln’s very helpful “Reshaping JSON with jq”. ↩