Part 1: Building the “Tweets of a Native Son” Archive (twarc and twarc-report)
So my project “Tweets of a Native Son” examines the way that Twitter conversations about Ferguson and the #BlackLivesMater movement invoke the literary author James Baldwin. What’s my archive? How did I build it?
Tweets can be ephemeral little stinkers. Since Twitter’s Search API only allows you to collect tweets from the last 1-2 weeks, foresight is huge when building a Twitter archive. Thankfully, Ed Summers had the foresight to start collecting tweets that mentioned “Ferguson” (upper or lowercase; with or without hashtag) in the weeks and months following Michael Brown’s shooting and, just as important, the generosity to share them openly. Though Twitter’s Terms of Service does not allow bulk distribution of Twitter data, it does allow the distribution of tweet “ids,” which are unique identifiers that get assigned to every tweet and can be used to retroactively access the full tweet metadata, a process called “hydrating” that can be performed with a command line Python tool like twarc, which was also created by Ed Summers. Yeah, Ed rules.
So the first step in building my Baldwin Tweet archive was hydrating the Ferguson tweet collections from both August and November, which you can perform by running the command twarc.py --hydrate:
mwalsh@ada:~/ferguson-tweet-ids/data$ gunzip ids.txt.gz
mwalsh@ada:~/ferguson-tweet-ids/data$ nohup twarc.py --hydrate ids.txt > tweets.json &
Since Twitter’s API rate limit only allows requests for up to 72,000 tweets per hour, this process took approximately 8 and 9 days, respectively. The utility “twarc-report,” created by Peter Binkley, allows me to generate a helpful, summarizing overview of these collections (# of tweets and users, top hashtags, top URLs, top images, etc.), which you can perform by running reportprofile.py with the flag -o text:
mwalsh@ada:~/ferguson-tweet-ids/data$ ~/twarc-report/reportprofile.py -o text tweets.json
mwalsh@ada:~/ferguson-indictment-tweet-ids/data$ ~/twarc-report/reportprofile.py -o text tweets.indictment.json
Here’s (some of) what the report spits out…
August Ferguson Tweet Collection
| Tweets: | 10,441,785 |
| Users: | 1,596,104 |
| Has Hashtag: | 6,898,701 (66.07%) |
| Hashtags: | 99,695 |
| Has URL: | 3,317,445 (31.77%) |
| URLs: | 664,691 |
| Has Image URL: | 1,593,403 (15.26%) |
| Image URLs: | 134,431 |
| Retweets: | 7,411,799 (70.98%) |
| Geo: | 74,678 (0.72%) |
| Earliest Tweet: | 2014-08-10 22:44:33 UTC |
| Latest Tweet: | 2014-08-27 15:15:50 UTC |
| Total Duration: | 16 days, 16:31:07 |
| Top Hashtags: | |
| 1. ferguson | 6,422,131 |
| 2. mikebrown | 583,141 |
| 3. michaelbrown | 158,552 |
| 4. justiceformikebrown | 84,061 |
| 5. tcot | 70,702 |
| 6. gaza | 70,338 |
| 7. stl | 58,662 |
| 8. handsupdontshoot | 47,126 |
| 9. darrenwilson | 40,091 |
| 10. fergusonshooting | 31,643 |
| Top URLs: | |
| 1. http://new.livestream.com/accounts/9035483/events/3271930 | 37,917 |
| 2. http://bzfd.it/VDlPH8 | 12,906 |
| 3. http://thebea.st/1l8uDRK | 10,773 |
| 4. http://bbc.in/1uS3tSd | 9,841 |
| 5. http://www.livestream.com/activistworldnewsnow | 8,276 |
| 6. http://wapo.st/1sXk4Sj | 7,535 |
| 7. http://es.pn/1AvncY9 | 7,514 |
| 8. https://vine.co/v/M3rWtqnrHi9 | 6,771 |
| 9. http://ind.pn/1qjd6lO | 6,366 |
| 10. http://ow.ly/ADgCF | 5,909 |
| Top Image URLs: | |
1.  |
21,899 |
2.  |
10,486 |
3.  |
10,319 |
4.  |
9,029 |
5.  |
7,956 |
6.  |
7,586 |
7. 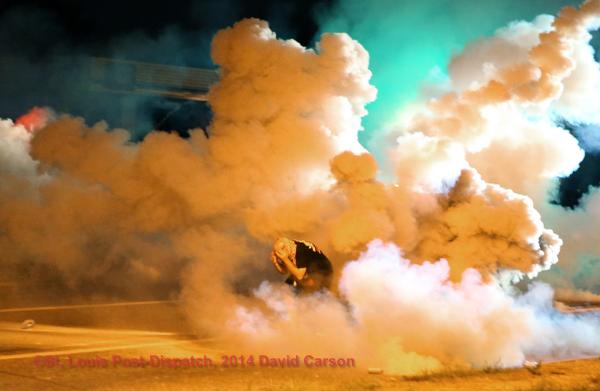 |
6,842 |
8.  |
6,223 |
9.  |
5,998 |
10.  |
5,195 |
November Ferguson Tweet Collection
| Tweets: | 7,868,540 |
| Users: | 1,761,950 |
| Has Hashtag: | 4,567,256 (58.04%) |
| Hashtags: | 110,097 |
| Has URL: | 3,514,869 (44.67%) |
| URLs: | 927,040 |
| Has Image URL: | 1,465,857 (18.63%) |
| Image URLs: | 191,684 |
| Retweets: | 5,004,081 (63.60%) |
| Geo: | 51,007 (0.65%) |
| Earliest Tweet: | 2014-11-11 22:17:06 UTC |
| Latest Tweet: | 2014-12-10 05:15:31 UTC |
| Total Duration: | 28 days, 6:58:25 |
| Top Hashtags: | |
| 1. ferguson | 3,969,513 |
| 2. mikebrown | 188,976 |
| 3. ericgarner | 178,139 |
| 4. blacklivesmatter | 151,749 |
| 5. fergusondecision | 118,405 |
| 6. michaelbrown | 105,607 |
| 7. tcot | 99,477 |
| 8. darrenwilson | 89,154 |
| 9. icantbreathe | 89,000 |
| 10. shutitdown | 45,296 |
| Top URLs: | |
| 1. http://cnn.it/1tAZkMJ | 11,592 |
| 2. http://nbcnews.to/12fXQ5f | 10,644 |
| 3. http://ble.ac/1B376rD | 9,848 |
| 4. http://invst.rs/7f2xJB | 8,609 |
| 5. http://nyp.st/1vjOX47 | 8,535 |
| 6. http://cbsn.ws/1vzqR5B | 8,097 |
| 7. http://bit.ly/1d5qTtO | 7,460 |
| 8. http://vine.co/v/On1x6iUuwxK | 7,396 |
| 9. http://on.rt.com/80mggq | 7,038 |
| 10. http://bit.ly/1vFrMUx | 7,028 |
| Top Image URLs: | |
1.  |
11,453 |
2.  |
10,907 |
3.  |
10,681 |
4.  |
10,004 |
5.  |
9,299 |
6.  |
9,190 |
7.  |
8,484 |
8.  |
7,870 |
9. 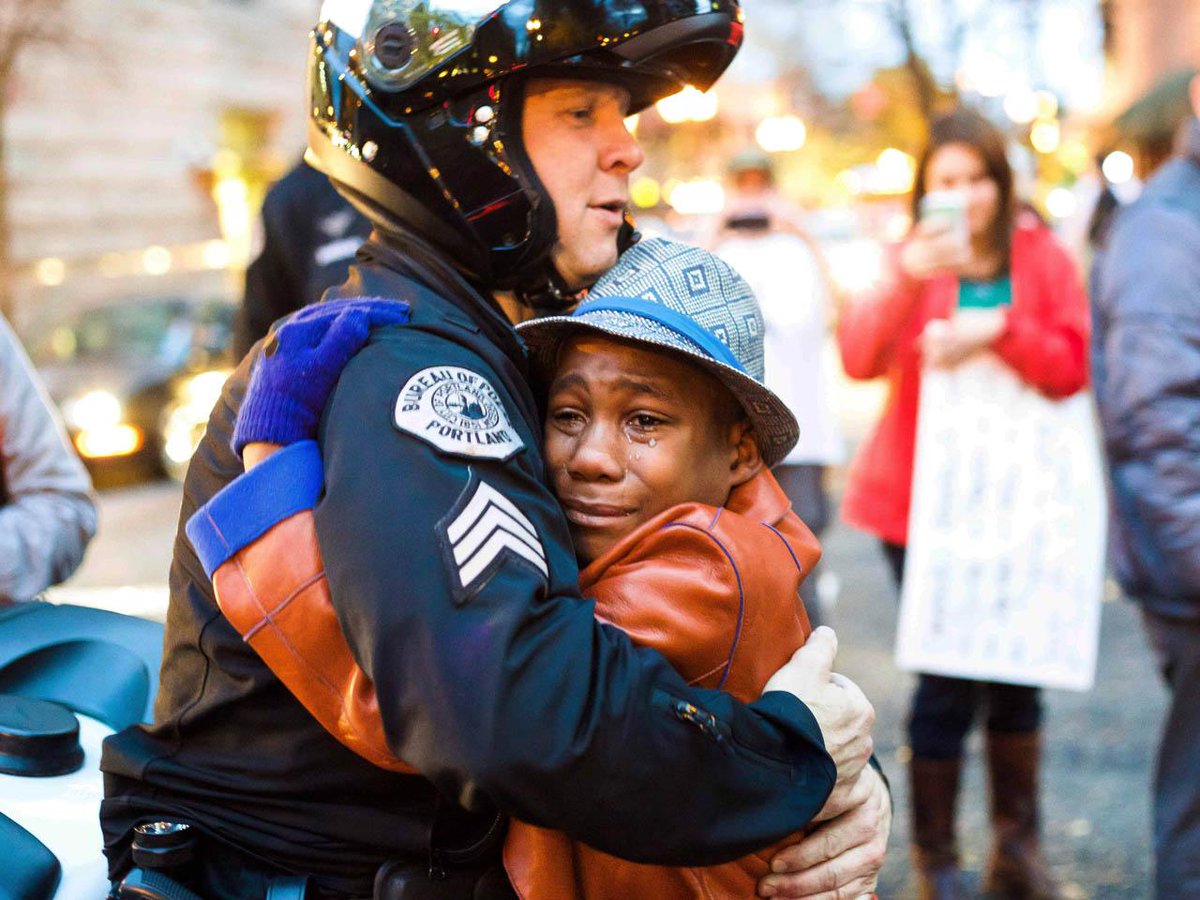 |
7,310 |
10.  |
5,824 |
This is a pretty cool macro view of over 17 million tweets, and it can already tell us a lot about what’s inside these datasets. For instance, from these summaries alone, we can see #BlackLivesMatter emerging into the mainstream conversation about Ferguson. From August 10 to August 27, the hashtag #BlackLivesMatter doesn’t even make the Top 10. But by November, it’s rocketed all the way to No. 4. These four months were crucial for the rise and circulation of the hashtag #BlackLivesMatter, and this data helps tell part of that story.
But of course this is not the whole story, and in fact it’s not even the whole Twitter story. After all, from the 13,480,000 tweet ids in the August collection and the 15,080,078 ids in the November collection, I was only able to hydrate 10,441,785 tweets and 7,868,540 tweets, respectively. That’s a lot of missing tweets. If you’re wondering where the heck all those tweets went, that’s an excellent question. If a Twitter user deletes his or her tweets before the time of hydration, that tweet gets lost forever. Poof! Ed Summers thinks this is a lowkey ethical move on Twitter’s part, which allows users the right to be forgotten. Spam also gets routinely and retroactively deleted from Twitter, which also might account for some of the missing tweets. Even so, this is still a rather large gap, and I hope to theorize it more fully in later posts.
For now, however, I’ll conclude Part 1 by saying that twarc is an awesome tool for creating Twitter archives if you know even a little bit about Python/the command line (though I should mention that Ed Summers is currently leading a project called “Documenting the Now” which aims to develop an even easier-to-use tool that requires no programming skills whatsoever) and twarc-report is a small but powerful utility for getting a sense of the contours of one’s dataset.
In Part 2, I will discuss how I narrowed these collections to only the tweets that mention James Baldwin (by using jq and regular expressions) and show what the twarc-reports of these smaller James Baldwin collections reveal.